
AI, Teamwork, and Biryani: Inside Fyle's In-Person Hackathon

Hi everyone, I am Sumrender Singh, MTS - 1 Frontend at Fyle.
In August, Fyle held an in-person internal hackathon and this blog details the experience of my team, the stuff we learnt and the idea we worked on.

Hackathon announcement
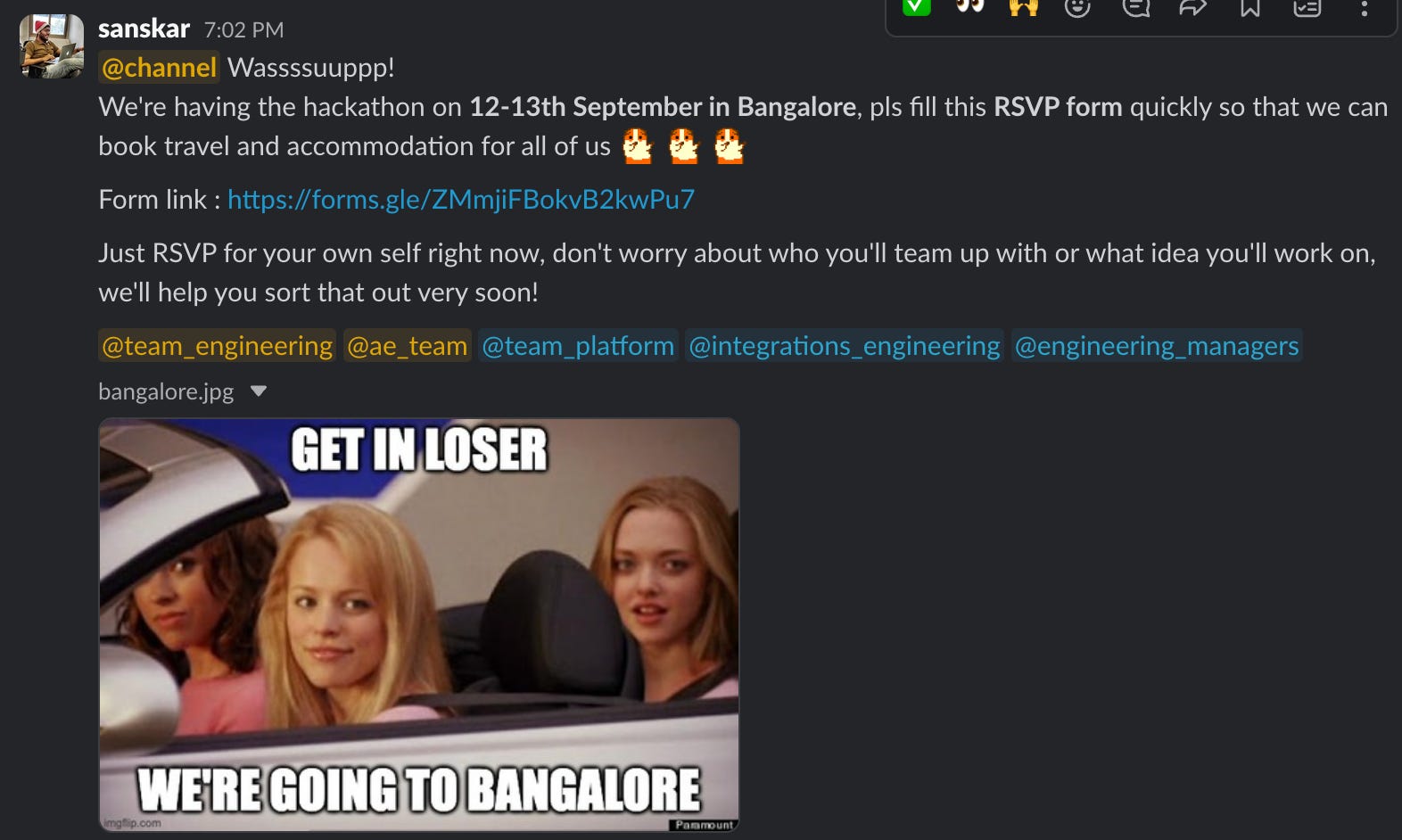
Around July 26th, the hackathon was announced. All of us were excited because it was going to be an in-person hackathon, meaning we’d get to travel, meet each other, and enjoy some good food.
The theme of the hackathon was Gen-AI, so we had to use it to build something that solves a problem or addresses an issue faced by either our customers or Fyle employees.
Team building
The hackathon date was finalized for September. Pretty far away, right? 😬 But soon enough, it was August 20th, and I still wasn’t part of any team. Thankfully, there were others like me, and as they say, birds of a feather flock together.
That’s how team Ctrl CV came to be. Our team consisted of:
Backend - Madan, Nandana
Frontend - Sruthi, Sumrender, Devendra
We had a good composition of both frontend and backend engineers.
Ideation
The next step was to decide on an idea. We had a thread going on the slack #hackathon channel where folks from different departments were discussing the problems they or the customers faced. Lot of nice ideas were already taken 🙃 and we weren’t even sure how we’d go about implementing the remaining ideas with AI. So, the first step was to learn about AI and LLMs—both of which were a complete black box for me.
How did I go about that? Thankfully, Sanskar had shared a "getting started" doc with some resources. I went through a few blogs from there. Then, curiosity got the better of me, and I started stalking other hackathon team channels to see what they were up to. I found a link to a LangChain course that we had access to. Over the weekend, I did a speedrun of the course to understand how LLMs can actually be used.

From the course, I got the basic gist of what LLMs are and how they can be used in applications. It mainly focused on LangChain, a Python framework for building applications with LLMs. The great thing about LangChain is that it’s model-agnostic—you literally just need to change one line of code to use a different model, and the rest of the code works as intended.
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash-latest")
# llm = ChatOpenAI(model="gpt-4o-mini")
After learning about LLMs, I again went back to the list of ideas. Now, I could see how I could go about implementing them. Our team decided to go with Intern Hiring, a universal problem that every manager rants about.

The Problem
Fyle’s engineering team focuses heavily on making interns successful and converting them to full-time roles. Most of the senior engineers here had started as interns back in the day. The hiring team, however, wasn’t too happy with the process. Sometimes, their entire day would go by just reviewing resumes—even after the initial filtering. On top of that, they also had to grade assignments, many of which were often blatant copies of someone else’s submissions.
Another major issue was the lack of a centralized data source. Each intern opening had its own separate Google Sheet, making it difficult to track things like how many times a candidate had applied or whether six months had passed since their last interview at Fyle.
(Fun fact: If you’ve interviewed at Fyle and weren’t selected, you can try again after six months. I myself got selected on my second try 😄).
There were also other challenges, like sending emails, creating Slack threads for ongoing interviews, and managing the overall hiring workflow.
To tackle all these problems, our team decided on creating an application to ease the hiring process. The idea is to create an app that can handle the following tasks:
Tracking Candidates: Maintain a database of candidates and update their status in the hiring process.
Grading Assignments: Use AI to evaluate test coverage and running tests; filter candidates with low coverage.
Assignment Test Case Summary: Summarize test cases that run when a candidate pushes code.
Reviewing Resumes: Analyze resumes with AI, summarize them, and score based on job fit.
Posting Updates on Slack: Use a bot to query hiring data and post pipeline updates.
Sending Emails: Allow one-click sending of acceptance, interview, or rejection emails.
Intuitive Frontend: Create a user-friendly UI for seamless interactions (Jo dikhta hai wahi bikta hai 😛).
Filtering Video Submissions: Automatically remove empty or irrelevant video submissions.
The last two features, unfortunately, didn’t make it into the final implementation due to time constraints… and definitely not because our entire team forgot about them until the day of the hackathon while preparing the presentation. 🫣
The “work” before start of hackathon
After deciding on the features, we divided the tasks among ourselves to create quick demos, ensuring we wouldn’t be stumped on the hackathon day. This planning happened about a week before the hackathon.
I took on the task of implementing the Resume Review feature, which wasn’t too complex. Here’s how it worked:
Extract all resumes from the Excel file.
Process the resumes to extract data.
Review the resumes based on the provided job description.
This involved interacting with the LLM model twice:
First Request: Format the resume data uniformly for review and storage in the database.
Second Request: Use the formatted data and job description to generate a score and a summary of the candidate’s experiences, projects, and how well their profile matches the job description.
The goal was to get an overall score and a concise summary of the candidate’s qualifications.
Since I finished this early, I also created a boilerplate frontend repository using the Angular framework. This was a bit controversial—using React could’ve allowed faster iteration—but the TypeScript support in Angular was a lifesaver. It helped us catch errors and debug issues during those frantic last-minute changes.

Hackathon start
On September 11th, most of the team arrived in Bangalore. The day was mostly spent meeting up, chatting with folks, and catching up with everyone from the engineering team. While talking to others, we learned that some teams were almost done with their projects—they just needed to fix a few bugs and prepare their presentations. Inspired, our team decided to gather and get some work done too.
We chose Python for our backend server since our backend team primarily works with Flask, and LangChain is a Python framework.
Here’s how we divided the work:
Devendra worked on creating the dashboard.
I shamelessly focused on the AI tasks because I had already done my share of frontend work with the boilerplate.
Sruthi fixed the code review service, which was plagued by AI hallucinations.
Nandana created the backend CRUD APIs.
Madan worked on GitHub Actions to ensure tests ran on every git push and extracted the test summaries from the actions.
Everything was going smoothly—until I hit a roadblock while saving data from the LLM model. For some reason, MongoDB just refused to connect. 😭

If it had been some other error, I might have accepted it—errors happen sometimes. But a MongoDB connection issue? The thing you set up first in every backend project and consider part of the boilerplate? This was betrayal—worse than Jon Snow killing his bua.
Frustrated, I went to bed still obsessing over what the issue could be. Was it the hotel Wi-Fi? Or maybe the pipenv package manager we were using in the repository?
The next day, after breakfast, we gathered in the conference hall for the official “start” of the hackathon. All of us got together in the banquet hall and got to work.
For the life of me, I still couldn’t connect the database to the server. 😭
When I checked with my teammates, they were mostly working on tasks that didn’t involve MongoDB—except for Devendra. He faced the same issue but quickly pivoted to creating a server using JavaScript, as he was integrating CRUD endpoints with the frontend.
I couldn’t do the same since all the AI code was in Python, and shifting everything to another language for one issue would’ve wasted a ton of time.
So, I did what every smart developer does after spending way too much time on a stubborn problem: I gave up… temporarily. Instead, I switched to another task and let the issue simmer in the back of my mind.
I created a JSON file and asked ChatGPT to whip up a quick script to save and extract data from it. Yes, I used a file as a database. It is what it is.

I continued working on ensuring that all the AI functions created by my teammates were working correctly and sending data in the expected format.
I also developed the entire upload flow, where a user could upload an Excel file, and the data would be extracted, parsed, and saved in the database.
The room was buzzing with energy. All the teams were seated at separate tables, working, chatting, and playing music. Some even took it a step further—sneaking over to unattended laptops at other tables to send “I’m getting married” messages on Slack. 😂
(Prakash, it definitely wasn’t me who left those messages from your laptop 😛)
It got to the point that we received this gem of a masterpiece from JB.

After stuffing myself with Chicken Biryani for lunch, I begrudgingly went to code again.
By this point, our team had a somewhat functional website, and the endpoints were up and running. And yes, the MongoDB connection issue was finally resolved—thanks to Madan, who switched to the pymongo library instead of flask_pymongo. 🙂
Devendra and Sruthi focused on the frontend, adding features like filters, sorting, and full list-view capabilities. Nandana, single-handedly, managed the creation and integration of the Slack bot. Meanwhile, Madan and I worked on optimizing API calls.
At this point in time, we had 1 webapp in Angular, 1 express server for
CRUD operations and 1 flask server for AI operations.
Currently the express server makes http api calls to the flask server for all AI related tasks.
Optimizing API calls
For each candidate there were a total of 3 AI functions being called.
For resume review
For code test summary
For code review
Initially, these calls were made sequentially, one after the other. However, since the functions don’t depend on each other, there was no need to wait for one to finish before starting the next.
Let’s say each AI function takes 2-3 seconds to complete. Sequential execution would result in a total wait time of 6-10 seconds per candidate.
To optimize this, I made the functions asynchronous and used asyncio.gather to run the API calls concurrently. This reduced the overall wait time by allowing the requests to execute in parallel without waiting for each other to complete.
Now, that was for a single candidate. But what about bulk reviews when a user uploads an Excel file and wants to review all candidate submissions?
At the time, we had no special functionality for bulk processing—just a simple for loop over the entire submissions array.
Disastrous, right? Even with optimizations, a single candidate taking 3 seconds would mean about 5 minutes for 100 candidates. Worse, the request would stay in a pending state, hogging CPU resources and slowing down the entire server. 😨
Any guesses on how we tackled this?
We threw a queue at the problem. 💃

As I mentioned earlier, at this point, we had two backend servers: an Express server and a Flask server. The Express server was making API calls to the Flask server for AI operations, with communication between the two happening via APIs.
To improve this, we decided to replace the API-based communication with a queue. Madan took on this task since he had already finished working on GitHub Actions and the code summary feature. The architecture of our application looked like this:

After dinner, we decided to gather in a room and continue working. Everything was falling into place nicely. With our second wind kicking in, we started thinking that if we pulled an all-nighter, we could even add more features. We could also dockerize and deploy everything online. Yeah right…
So, I decided to work on the presentation. Initially, I tried using some AI-powered presentation tools. They gave me a nice basic layout, but the downside was that I could only edit the text and slide layout—I couldn’t move individual elements. Frustrated, I tried exploring other websites.
By the way, I was creating the presentation while lying on a bed. And soon enough, I felt like taking a “short nap.” Spoiler alert: it was not a short nap… 😴

The day of presentation
I woke up around 6-7 a.m., knowing it was do or die now. I quickly started working on the presentation. Those AI presentation websites didn't let me download the presentation in .pptx format—only PDF was available in the free tier.
All my smugness about not having to spend a lot of time on the PPT went out the window, and I grudgingly moved to Canva and duplicated the designs there.
Pro Tip: Canva Pro is only Rs 69 for one day, so you can use it for creating awesome presentations.
I myself came to know about this later only. 🫠By now, my teammates had also gathered and were wrapping up their tasks. At this point, we were almost done—except for Devendra, who wanted to host everything online. Madan tried using Docker, but errors started popping up left and right. So, we decided to use Render to host the web app and the Express server, while the Python Flask server was hosted using ngrok. We then headed to the conference hall for the presentations.
Soon enough, the presentations began after the judges arrived. The judging panel consisted of the big bosses: Siva, Yash, Vik and Bhardwaj. There were a lot of great ideas presented. Some teams developed full features for the web app that could be useful for customers, like a Spotlight feature for navigating anywhere or searching for any settings.
One team created a chatbot trained on Fyle’s GitHub repositories. It produced highly relevant code and helped resolve doubts. They even took my testimonial for the bot but didn’t include it in their presentation. (🔪)
There were plenty of interesting projects, and, as usual, many demos went haywire—completely at the mercy of the Demo Gods.
Soon enough, it was our turn, and Devendra took the lead in presenting. I sat at the computer, ready to press the arrow keys and switch browser tabs. 🤠
After our introduction, it was time to show the working demo… and the server stopped responding. 🙃
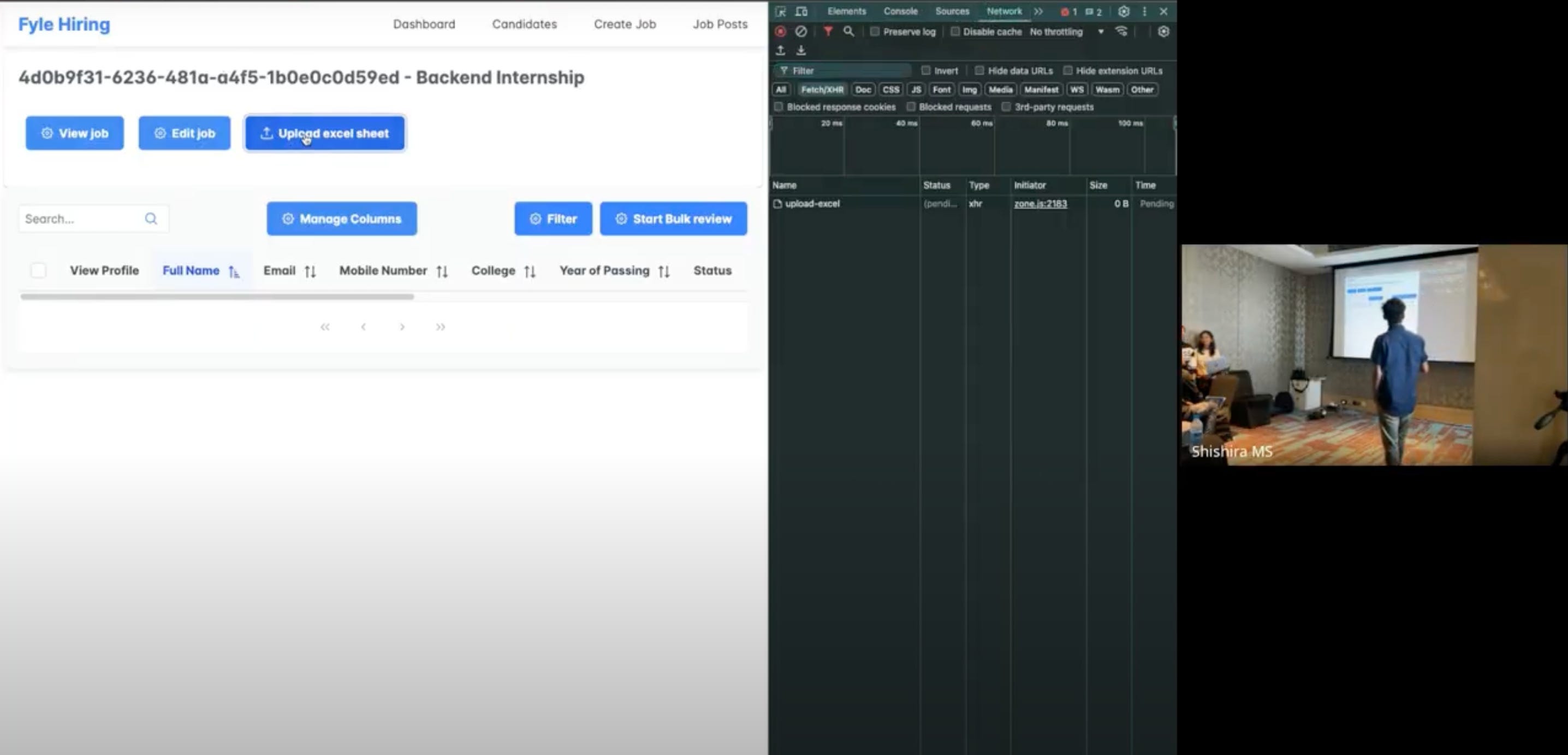
Our team already knew the reason. If you don’t interact with a Render application, it spins down the instance—and our Express server was hosted on Render. We were aware of this and had been making periodic requests to keep it running. But while watching other teams’ presentations, we forgot to do this. 💀
This led to an impromptu debugging session. Thankfully, everyone assumed it was just an internet issue since the requests were showing as "pending" in Chrome’s network tab.
We eventually got it running and finished the presentation. After every team’s demo, there was a short break, and then it was time for the results.
You can watch our presentation here.
Results

The winner of the hackathon was Team Rabdi Jalebi (Aiyush, Prakash, Suyash, Garvit). They tackled a major pain point for the Implementation team. Whenever a new business is onboarded, a sheet is filled out based on their requirements, and then the Implementation Executive manually creates a demo account for the business.
Team Rabdi Jalebi’s solution automated this process. Their implementation took the sheet filled out by the business and automatically created a demo account based on it. The Implementation Executive only had to verify that everything was correct, and the same configuration could then be used to create a real account. This eliminated the need for manual setup and saved a lot of time, which could be spent handling other requests.
Apart from the winner’s prize, there was another award: Crowd’s Favourite. For this, everyone had to vote using a Google Form (but couldn’t vote for their own team). Somehow, our team won this award. 🤯
Honestly, there were projects far better than ours, but I think what people liked about our project was the completeness of our implementation. We covered everything—from the web app to Slack integration, email functionality, and even GitHub Actions. At least, that’s my best guess!

Learnings
This hackathon was a great initiative. Thank you Sanskar for organising this 🙏. Due to this hackathon I got to learn a lot of things namely:
Knowledge about LLMs which was earlier like a blackbox
Prompt Engineering and Retrieval Augmented Generation
Working with Python, Flask, Langchain framework
Got to know about Redis Queue and used the same
Most of all, thinking about a problem from the customer’s side and then working towards a solution.
Awesome work Team CtrlCV!! Great learnings shared✨
Good stuff.