
Analytics Pipeline Using Incremental Refresh at Fyle

As a product scales, there is a spike in the incoming data. More importantly, there is an increase in the amount of incoming data for certain core objects of the product ( expense (fyled) and expense reports (submitted) in case of Fyle ) - these core objects become very critical to the performance of the product and their engineering design (all from application layer to persistence layer) needs to be optimal to continuously scale the whole product.
At database level, the tables of these fast moving objects are bombarded with increasing number of OLTP queries. Running other queries (for non-core business aspects) - such as analytics and MIS - degrades the perf of all queries and adversely affects application.
Common approach to analytics is to have a set of normalized tables and load data from core /fast-moving (source) tables to these separate views/table definitions (destination) - optimised for running complex analytical queries
This ETL operation of moving data from source table to the destination table will be referred to as refresh in this blog post.
We had started with PostgreSQL materialized views to create normalized table definitions for our analytics sub-system. Materialized views are persisted database views. Unlike normal views, their underlying query is not executed every time they are accessed, instead they have a refresh mechanism to update the data.
Refreshing our view used to take ~55 minutes and this was not acceptable. This post describes what we did to bring it down to 30 seconds using incremental refresh. Read on to find out how we achieved this greater than 100x improvement.
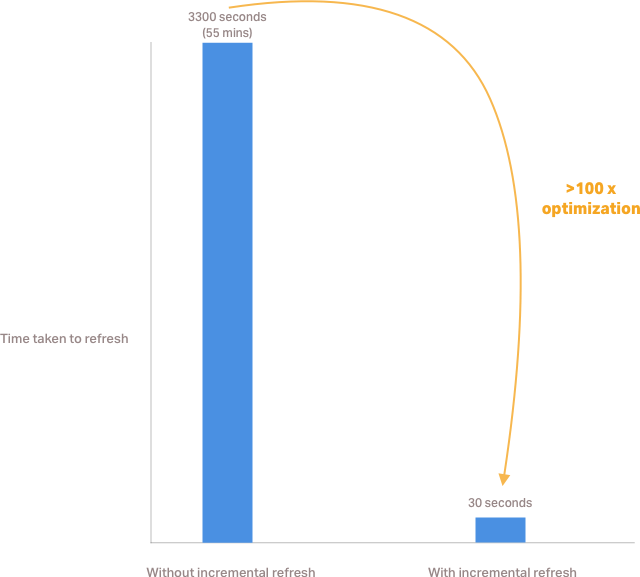
Our data refresh problem
As I mentioned, for our analytics data store, we had started with using PostgresSQL materialized view, which took ~55 mins to refresh, and this refresh duration was increasing gradually with data. We cannot add new rows to materialized view selectively so incremental refresh using it was not possible.
We ran the refresh every 3 hrs at first - and soon realised that it is killing our database performance. When the view refresh ran, all queries which involved our core tables slowed down, some even timed out - this was leading to inconsistency at application level. We decided to run the refresh every 24 hours when the application traffic was lowest, as a temporary work-around.
Many tools just decide to show a 24 hour delay in analytics. We wanted to keep the data delay down to an hour and make our analytics as close to real-time as possible.
So we had to figure out a way to refresh data at much shorter intervals, without killing our database performance.
How we implemented incremental refresh
The idea is - to fetch only newly created and updated rows from source table and add them to destination table - at regular intervals of time (say every 1 hour) - and run full refresh (i.e fetch all rows from source table) after a longer interval (say once a week) to make sure no inconsistencies exist.
To explain our methodology, I'm going to present a highly simplified version of our problem. Consider we have a database schema with one fact table (say bills) and one dimension table linked to it (say payments).
Table structure as follows :
bills (id, created_at, updated_at, amount, payee_name, payer_name)payments (id, created_at, updated_at, status, paid_date, bill_id)Here payments is linked to bills using bill_id as foreign key.
Now we need a mechanism to incrementally sync data from these core tables to a corresponding analytics table - say bills_extended.
Table structure as follows :
bills_extended (bill_id, bill_amount, created_at, payment_id, payment_status, paid_at) To implement incremental refresh:
we can simply fetch all bill ids created or updated in a time interval (last 1 hour or 24 hours whatever) and store them in a temporary table bill_ids.
CREATE TABLE bill_ids (id INTEGER UNIQUE) ;
INSERT INTO bill_ids (
SELECT id FROM bills WHERE updated_at >= (NOW() - <time-interval>)
) ;And then simply execute the bills_extended table definition for these ids and upsert these rows in the bills_extended table using on conflict.
INSERT INTO bills_extended
(
bill_id, bill_amount, created_at,
payment_id, payment_status, paid_at
)
(
SELECT
b.id, b.amount, b.created_at,
p.id, p.status, p.paid_at
FROM bills b
JOIN bill_ids ON bill_ids.id = b.id
JOIN payments p ON p.bill_id = b.id
)
ON CONFLICT (bill_id) DO UPDATE SET
(
bill_id, bill_amount, created_at,
payment_id, payment_status, paid_at
) = (
EXCLUDED.bill_id, EXCLUDED.bill_amount, EXCLUDED.created_at,
EXCLUDED.payment_id, EXCLUDED.payment_status, EXCLUDED.paid_at
) ;Done. Super. But wait ... there is one problem.
Consider this scenario - payment status for a bill (say bill id 4) was changed from PENDING to PAID but the bill itself was not updated - i.e the row with id 4 in the bills table was not updated in any way.
So now - when the refresh runs - bill id 4 will not be included in the bill_ids table which contains all recently created/updated rows and so - for bill id 4 , the payment status in the bills_extended table will still be shown as PENDING while in source table (payments) it is PAID.
So the problem is that changes in dimensiontables will not be considered if we only chose to refresh on updation/creation of facttable rows
To avoid this scenario, we need to consider dimension table upserts also in our refresh. In our case, we will need to include (in refresh) distinct bill ids of payments table which were updated/inserted in the incremental refresh duration.
INSERT INTO bill_ids (SELECT DISTINCT bill_id FROM payments WHERE updated_at >= (NOW() - <time-interval>)) ;This was just an example to demonstrate the fundamental approach for incremental refresh, nowhere close to how things pan out in production systems.
In real world applications, there would not be just one but tens of fast-moving dimension tables which will need to be included in the incremental refresh.
How to determine which tables to ‘include’ in your incremental data refresh
It mainly depends upon your business logic : which objects/tables are more important ? which objects/tables are fast-moving ?
To objectively determine this, we analysed the rate of incoming data per unit time for different dimension tables. This involved digging into the audit trails data and finding out :
how many rows were upserted per hour for a dimension table
how many distinct fact table rows were affected per hour due to dimension table upserts.
This gave us info about which dimension tables were fast-moving - a stat which decided which all tables to consider for including in incremental refresh.
Another little problem : removing deleted data
Earlier with PostgreSQL materialized view, we didn’t have to worry about deleting rows which were deleted in the source tables ; the whole view was re-computed on every refresh and all the deleted rows were removed automatically. But now in our custom refresh implementation we have to take care of removing deleted data.
A simple way of doing this would be to delete all rows from analytics table which are not present in the source table, before refresh runs. This would be done before every refresh - it can be a part of the refresh process itself. Though this is a simple and straightforward solution, oftentimes its an expensive query in production systems i.e if the source table (bills in our example) is pretty big - as it turned out in our case. As a solution, we stored ids of all deleted rows for our core fact tables - and took care of removing deleted rows from our database using those ids. There are other cases where even this might not be needed. Like if soft delete pattern is implemented for deleting data from your product, there is no need for removing data in refresh mechanism.
Implementation notes
Our whole refresh process was driven through pl/pgsql functions - reasoning for using pl/pgsql functions was :
We wanted the data-refresh logic to live close to the data for better control and performance
We wanted to have a single point of entry for our refresh mechanism - so it's easy to maintain and execute
In essence - there is one main function for refresh which triggers other functions for executing different steps along the refresh process. Some logical segments in which our refresh process is divided into, are : preparing list of ids to refresh, removing deleted rows, preparing intermediate tables required for refresh, dropping temp tables and other clean up tests after refresh is completed. We have separate functions for every such step.
In Conclusion ...
Short refresh timings (30 secs for incremental refresh every hr) made it possible to refresh our reporting/analytics data-store without affecting our database performance.
Solving this data refresh problem enabled us to solve many other problems eventually. We built a comprehensive search and reporting service on our analytics data-store since the data is better structured - leading to a better MIS offering from Fyle. Also, analytics is now very close to real-time as our data-store is updated every hour - something which troubles even the biggest and best of products/companies.
We talked about refreshing data from fact tables and dimension tables to a separate table definition which can be used for serving analytical queries. But we didn't talk about refreshing data for summary tables in analytics.
This is another interesting problem which we are solving at Fyle. If you enjoy taking up such challenging engineering problems, mail us at [email protected] :)