
🚀 Automating Data Migrations at Fyle

Hello, I’m Shreyansh 👋🏼, part of the engineering team at Fyle. Today, I want to share our journey of transforming how we handle Data Migrations—a process that's critical, yet often challenging.
What Are Data Migrations?
Before diving into our journey, let's clarify what we mean by data migration. At its core, a data migration is the process of moving, transforming, or updating data within your database systems.
At Fyle, our data migrations are primarily focused on database operations:
Backfilling data: Adding missing information to existing records.
Schema updates: Moving data between tables when structures change.
Data cleanup: Standardising formats, removing duplicates, fixing inconsistencies.
Business logic updates: Restructuring data to reflect new requirements.
🚩 The Initial Approach & Its Pitfalls
Initially, our data migrations were manual. There was no standardised structure, i.e., everyone had their own way of writing and executing scripts.
Example:
We had to update the data stored in
notification_settingscolumn in ouruser_preferencesThis needed a data backfill if the older data
email_frequencystored innotification_settingsis empty and which were created before 1st January 2024.
UPDATE user_preferences
SET notification_settings = jsonb_set(
notification_settings,
'{email_frequency}',
'"weekly"'::jsonb
)
WHERE created_at < '2024-01-01'
AND notification_settings->>'email_frequency' IS NULL;
Though straightforward, this approach caused serious problems:
Long Execution Times: Large operations took hours and were dependent on incoming traffic.
Impact on Production Traffic: Heavy updates block the rows that are being updated, leading to slower queries, application timeouts, and user disruptions. (We use PostgreSQL as our database)
No Monitoring: With ad-hoc running of scripts, there was no way to track the progress of rows that were migrated.
🛠️ The Breakthrough: Batch Processing
We knew we needed to break large operations into smaller, manageable chunks. The concept was simple: instead of updating thousands of rows at once, we split migrations into batches of 50 to 200 records.
We developed a standardised SQL template that became our go-to pattern:
-- The batch-wise approach that saved our sanity
WITH batch_data AS (
SELECT id,
row_number() OVER (ORDER BY id) as row_num
FROM user_preferences
WHERE created_at < '2024-01-01'
AND notification_settings->>'email_frequency' IS NULL
),
batch_ids AS (
SELECT array_agg(id) as ids
FROM batch_data
WHERE row_num BETWEEN 1 AND 1000 -- Process first batch
)
UPDATE user_preferences
SET notification_settings = jsonb_set(
notification_settings,
'{email_frequency}',
'"weekly"'::jsonb
),
updated_at = NOW()
WHERE id = ANY((SELECT ids FROM batch_ids));
-- Then manually increment the BETWEEN range for next batch
-- BETWEEN 1001 AND 2000, then 2001 AND 3000, etc.
⚡The Immediate Improvements
This approach gave us breathing room:
Standardization: Other developers could understand and use the same pattern.
Reduced Timeouts: With smaller batched updates, users faced little to no disruption in the application.
Resumability: If something failed, we knew exactly which batch to resume from.
Production Friendly: Application performance remained stable during migrations.
But it came with its own challenges:
Manual Execution: We still had to manually run each batch and track progress.
Human Error: Easy to miss a batch or run the same batch twice.
Failed batches: Failed batches required manual investigation and re-execution.
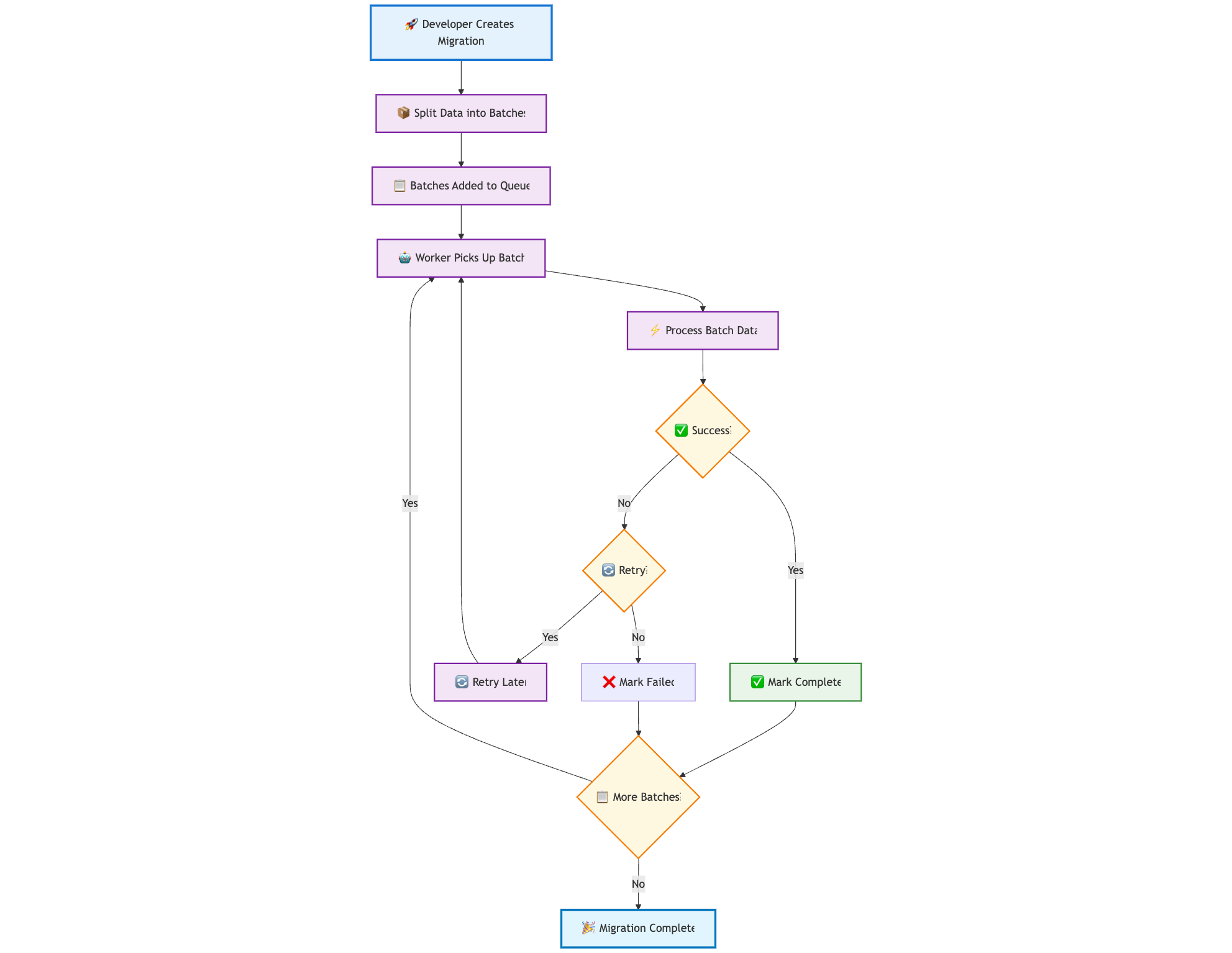
🤖 Automating Batch Processing
The batch approach worked, but the manual overhead of running the batches was still not effective. We were spending more time running these migrations than building features.
We introduced a Data Migration Worker System—a Python worker that continuously fetches batches from a dedicated table and executes them automatically.
The Core Architecture
We introduced three key components:
1. The task_batches table
This table was the command center – every batch is tracked from creation to completion.
CREATE TABLE task_batches (
id SERIAL PRIMARY KEY,
migration_version TEXT NOT NULL,
entity_ids TEXT[] NOT NULL,
handler_procedure TEXT NOT NULL,
created_at TIMESTAMP DEFAULT NOW(),
started_at TIMESTAMP,
completed_at TIMESTAMP,
failed_at TIMESTAMP
);
2. The worker_config table
This gave us runtime control over the migration process without code deployments.
CREATE TABLE worker_config (
is_enabled BOOLEAN,
query_timeout_ms INTEGER,
processing_interval INTEGER
);
3. The Python Worker
A continuously running process that polls for new batches and executes them, and adds a backoff for processing:
class DataMigrationWorker:
def run(self):
while worker_running:
if config.is_enabled:
set_statement_timeout()
process_next_batch() # Runs a procedure
sleep(config.processing_interval)
Process Batch Procedure
CREATE PROCEDURE proc_execute_batch(batch_id INTEGER)
LANGUAGE plpgsql AS $$
BEGIN
UPDATE task_batches
SET
started_at = NOW()
WHERE
id = batch_id;
BEGIN
EXECUTE handler_procedure(entity_ids);
UPDATE task_batches SET completed_at = NOW() WHERE id = batch_id;
EXCEPTION
WHEN OTHERS THEN
UPDATE task_batches SET failed_at = NOW() WHERE id = batch_id;
END;
END;
$$;
The New Migration Workflow
Now, creating a migration has become as simple as:
Write a stored procedure that handles a batch of IDs; this is basically what you want to update:
CREATE OR REPLACE PROCEDURE proc_update_user_notifications(entity_ids text[])
LANGUAGE plpgsql AS $$
BEGIN
UPDATE user_preferences
SET notification_settings = jsonb_set(
notification_settings,
'{email_frequency}',
'"weekly"'::jsonb
),
updated_at = NOW()
WHERE id = ANY(entity_ids)
AND notification_settings->>'email_frequency' IS NULL;
END;
$$;
Generate batches with a single query (what we had earlier improved with batch processing):
WITH records_to_migrate AS (
SELECT id,
(row_number() OVER ()) / 200 AS batch_id
FROM user_preferences
WHERE created_at < '2024-01-01'
AND notification_settings->>'email_frequency' IS NULL
),
batch_grouping AS (
SELECT batch_id, array_agg(id) AS entity_ids
FROM records_to_migrate
GROUP BY batch_id
)
INSERT INTO task_batches (
migration_version,
entity_ids,
handler_procedure
)
SELECT
'v125_update_user_notifications',
entity_ids,
'proc_update_user_notifications'
FROM batch_grouping;
Let the worker handle the rest – it would automatically process all batches at a controlled pace.
⚠️ Learning from Failures
Initially, automation was effective—until batches began failing due to intermittent issues, such as database timeouts. Manually reprocessing failed batches wasn't scalable.
We added two new columns to task_batches table to handle this
CREATE TABLE task_batches (
...
retry_count INTEGER DEFAULT 0, -- Current attempts of batch (if failed)
max_retries INTEGER DEFAULT 3 -- Max attempts allowed to a batch.
);
We then updated our batch execution procedure to include automatic retries of failed batches with backoff at the worker level:
CREATE PROCEDURE proc_execute_batch(batch_id INTEGER)
LANGUAGE plpgsql AS $$
BEGIN
-- Fetch one unprocessed batch at a time
UPDATE task_batches
SET
started_at = NOW(),
retry_count = retry_count + 1
WHERE
id = batch_id AND
completed_at is NULL AND
retry_count <= max_retries; -- This will automatically pick up failed batches.
BEGIN
EXECUTE handler_procedure(entity_ids);
UPDATE task_batches SET completed_at = NOW() WHERE id = batch_id;
EXCEPTION
WHEN OTHERS THEN
UPDATE task_batches SET failed_at = NOW() WHERE id = batch_id;
END;
END;
$$;
Auto-retry made migrations resilient, automatically retrying failed batches up to their max_retries.
💻 Monitoring and Observability
All batches have clear timestamps (created_at, started_at, completed_at, failed_at) providing transparent monitoring capabilities.
We added Grafana dashboards, which made it easier to track progress and set up alerting on failures.
↗️ Flow Diagram
📈 Results:
The transition from manual to automated migrations has delivered measurable improvements:
What used to take a developer 5-6 hours (or even more if it involved a large migration) to manage SQL queries now completes automatically. Engineers spend 90% less time on migration tasks, freeing them to work on product features.
Previously, large migrations would cause application timeouts. Now, users experience no disruptions.
Failed migrations that once required 1-2 hours of manual intervention and debugging now auto-recover within minutes.
🚀 Looking Forward
We've significantly reduced operational risk and improved migration efficiency at Fyle. This transformation allows developers to focus on building great features rather than firefighting risky migrations.
Well written article! 🙌🏻
Thanks for explaining it in so much detail. 😊