
Demystifying Grouping sets In Postgres

Hello there! I'm Kartikey Rajvaidya, Engineering Manager at Fyle. My journey with Fyle has spanned over half a decade, and during these ~5 years, I've had the privilege of being an integral part of the Fyle Engineering team. In this blog, I’ll shed light on an intriguing topic in the realm of Postgres: Grouping Sets.
One of the most common tasks when working with relational databases is aggregating data using grouping operations. Grouping sets are a powerful feature in PostgreSQL that allows us to aggregate data based on multiple dimensions, providing a more detailed view of the data.
Grouping sets allow us to define multiple grouping levels within a single query. Instead of writing multiple queries to produce the desired report, we can use grouping sets to generate the report in a single query. This can be especially useful when dealing with large data sets. because the time taken to read the data is often the bottleneck for performance. In such cases, it is desirable to read the data once and generate multiple results simultaneously. This is precisely what can be accomplished with GROUP BY GROUP SETS.
In this blog post, we will explore grouping sets in PostgreSQL and will compare the query performance with and without grouping sets.
To Understand Grouping sets better let's take an example of an expense management application where we have 2 tables
Employees
- id Primary Key
- full_name
Expenses
- id Primary Key
- amount
- employee_id FOREIGN KEY REFERENCES Employees(id) ON DELETE CASCADE
- category_name Not null
We need to determine the following information:
Money spent on each category.
Overall money spent by each employee.
Money spent by each employee in a particular category
Let's first find this data and analyse the query without using Grouping sets
-- This will give us Money spent on each category.
-- This will give us Money spent by each employee in a particular category
SELECT employee_id, category_name, SUM(amount) AS total_spent
FROM Expenses
GROUP BY employee_id, category_name
UNION ALL
-- This will give us Money spent on each category.
SELECT
NULL AS employee_id,
category_name,
SUM(amount) AS total_spent
FROM Expenses
GROUP BY category_name
UNION ALL
-- This will give us the Overall money spent by each employee.
SELECT
employee_id,
NULL AS category_name,
SUM(amount) AS total_spent
FROM Expenses
GROUP BY employee_idAlthough the query we used to retrieve the necessary data was straightforward, it involved several steps. We had to write three separate queries, each with a distinct GroupBy condition, to obtain the three distinct datasets we needed. Finally, we combined the results using the Union operator. While the query works as intended, it is quite lengthy.
Now let's check out the query plan to see how the query is performing
QUERY PLAN
----------------------------------------------------------------------------------------------
Gather (cost=5800.58..10603.69 rows=23 width=47)
Workers Planned: 2
-> Parallel Append (cost=4800.58..9601.39 rows=9 width=47)
-> HashAggregate (cost=5352.01..5352.20 rows=15 width=44). -- FIRST SCAN ON THE EXPENSES TABLE
Group Key: expenses.employee_id, expenses.category_name
-> Seq Scan on expenses (cost=0.00..3697.72 rows=220572 width=18)
-> HashAggregate (cost=4800.58..4800.64 rows=5 width=44) -- SECOND SCAN ON THE EXPENSES TABLE
Group Key: expenses_1.category_name
-> Seq Scan on expenses expenses_1 (cost=0.00..3697.72 rows=220572 width=14)
-> HashAggregate (cost=4800.58..4800.62 rows=3 width=68) -- THIRD SCAN ON THE EXPENSES TABLE
Group Key: expenses_2.employee_id
-> Seq Scan on expenses expenses_2 (cost=0.00..3697.72 rows=220572 width=10)
(12 rows)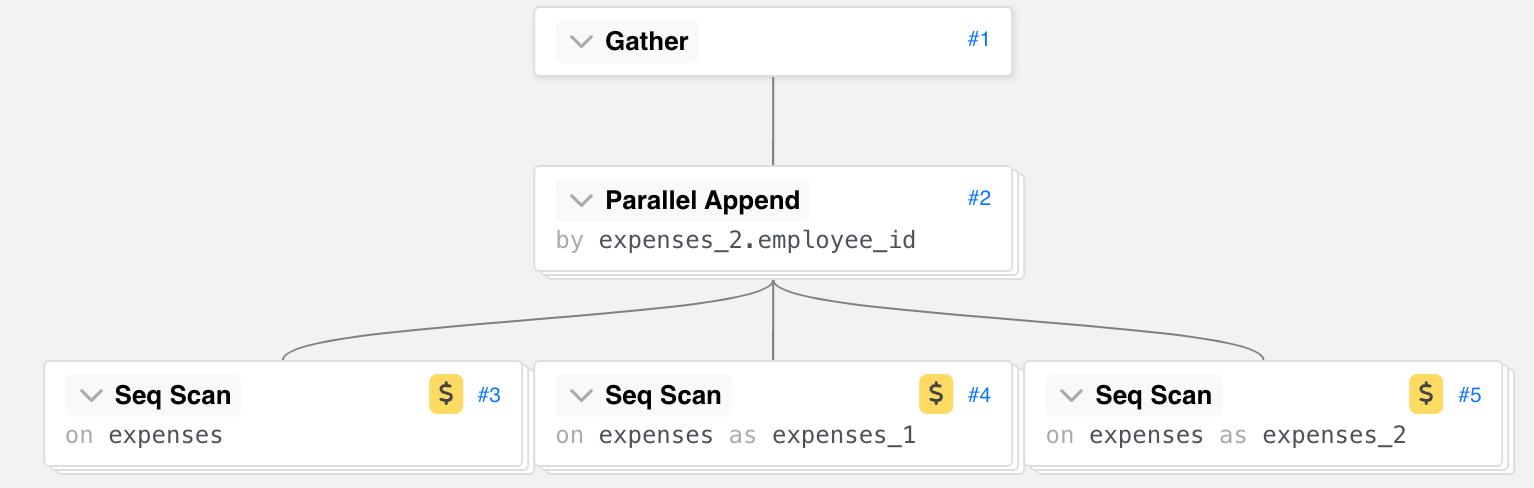
The above plan clearly shows that PostgreSQL has to scan the expenses table thrice separately for each query which is certainly not efficient
Now let's see how can we write the same query Leveraging Grouping sets
SELECT
employee_id AS employee_id,
category_name AS category_name,
SUM(amount) AS total_spent
FROM Expenses
GROUP BY GROUPING SETS (
(employee_id, category_name),
(category_name),
(employee_id)
)
ORDER BY employee_id, category_name;wow, that was so easy, This query is much shorter and more readable. The above query successfully resolved the initial problem we encountered with the first query, which was its excessive length. By declaring our three different group sets within a single query, we were able to achieve the same outcome that would have otherwise required us to write three separate queries.
Now let's check out the query plan to see how the query is performing
QUERY PLAN
-----------------------------------------------------------------------------
Sort (cost=7556.56..7556.62 rows=23 width=44)
Sort Key: employee_id, category_name
-> HashAggregate (cost=5350.75..7556.04 rows=23 width=44)
Hash Key: category_name, employee_id
Hash Key: category_name
Hash Key: employee_id
-> Seq Scan on expenses (cost=0.00..3697.00 rows=220500 width=18)
(7 rows)
The plan above demonstrates that utilizing Grouping sets has resolved our second concern as well, which was the query scanning the same table three times.
With this approach, the entire table is scanned only once, thereby improving efficiency.
In conclusion
In this blog, we have seen the following advantages offered by grouping sets
Improved Performance: By grouping multiple levels of data in a single query, grouping sets can significantly reduce the number of queries required to retrieve the same information, leading to better performance and faster results.
Simplified Query Construction: With grouping sets, it is possible to create complex queries with multiple groupings and subtotals using a single query statement, rather than having to create and execute multiple separate queries.
Easier Maintenance: With grouping sets, queries are more concise and easier to read, making them simpler to maintain and update over time.
What's next
If the readers find this blog post helpful, In the next part We will explore how we can further simplify GROUPING SETS for more intricate needs by utilizing ROLLUP and CUBE functionalities.
Happy querying
Hey Kartikey, good insights into this grouping sets feature. Although, you might want to fix the sql comments in the individual queries.