
How did we increase Data Extraction accuracy by a whopping ~50%?

What if I were to tell you that you have to enter receipt details manually for your business expenses to get reimbursed, sounds painful right?
Hey there, I am Madhav Mansuriya, I joined Fyle as an intern back in 2019 (even before I graduated I was a part of Fyle 😛, lucky me!) and now I own an entire module called Data Extraction (DE). From fixing small bugs to re-writing the whole mobile app and DE service, I have evolved a lot!. Today I wanna share a small story of how we improved our Data Extraction accuracy by 50%.
This journey taught me, from how to work as an intern to how to work with an intern!
What is Data Extraction?
We at Fyle strive hard to reduce/remove any manual effort needed from our users to submit their business receipts and we think it a magical experience!
The capabilities of our module helps us in making the experience of submitting expenses buttery smooth, just click the photo of the receipt, sit back and relax 🏖

Once the receipt is uploaded all the required data from the receipt will be automatically extracted and your expense will be submitted. Hard to believe right? I know! that is why I said it is magical.
Our system is so robust that it supports various types of receipts, currencies, vendors, and whatnot! Don’t believe me? See for yourself
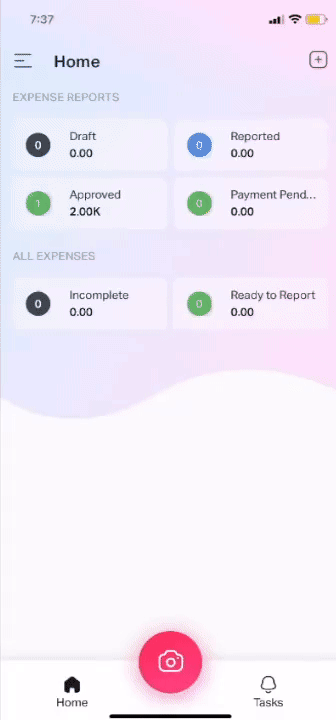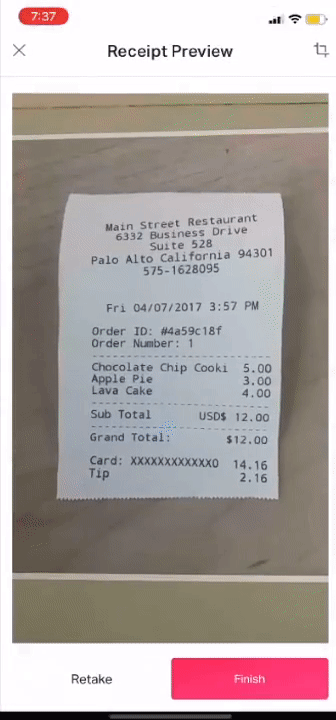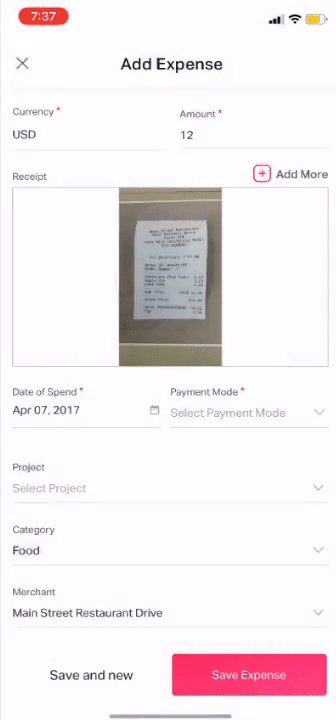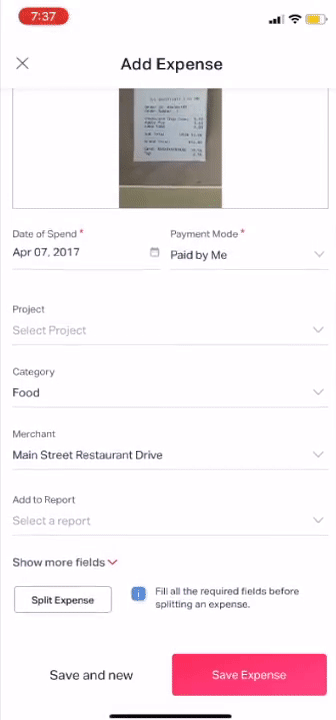
How does the DE module work?
Fyle supports paper(photo of the receipt) and digital(PDF invoices and email forwards) receipts. When the user uploads the receipt/invoice from any client (web app, mobile app, email forwards, etc.) our DE module comes into play.
Earlier we used to use Google Vision to extract the data from the receipt, our models built on top of Google Vision try to find the required details like Amount, Currency, Date of Spend, Category of Spend, and Merchant.
To extract details like the amount and category we had machine learning models that helped in classifying and extracting the required data.
Receipts of different currencies would have details about the date and currency present in all kind of formats and positions, our smart logic layer made it very easy to extract and classify the relevant info.
Guess what? The trickiest part in the receipt is extracting the merchant name, extracting it is very difficult because of a few reasons like thousands of merchants across the globe, hundreds of fonts, tons of receipt formats, and a combination of all these makes it extremely difficult to extract the merchant name with very high accuracy.
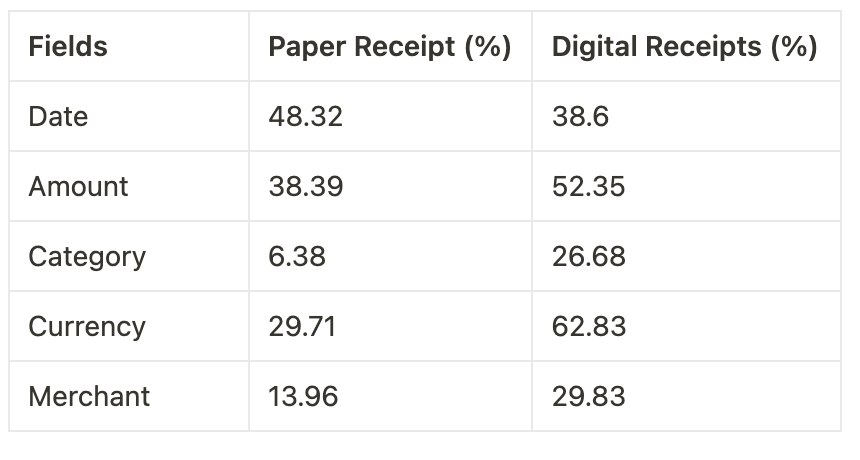
What was the accuracy before?
What the heck is accuracy?: Accuracy here means how many data points are getting extracted from the given set of receipts
How is accuracy calculated?: It is calculated based on what people like you and me would see in a receipt vs what the machine learning model would extract
What magic did we do to get to our goal?
We were using the old model for almost 5+ years and a boost in accuracy was long overdue. We named our experiment DE-v2, we had heard about Amazon Textract which helps in synchronously analyzing an input receipt/invoice for financially-related relationships between text!
Let us go on a little technical joy ride? Shall We?
It was time to experiment with Textract and we did some research and built a bunch of POCs.
Like with all experiments, some failed quickly, some others failed rather horribly, but I strongly believe in the words, Success is sweet, but the secret is sweat.
We ended up getting some good results with the following two APIs:
Detect Document Text: It helped us to get simple OCR from the receipt
Analyze Expense: It synchronously analyzes an input receipt for financially-related relationships between text. Ex: Amount, Date, Merchant name, etc.
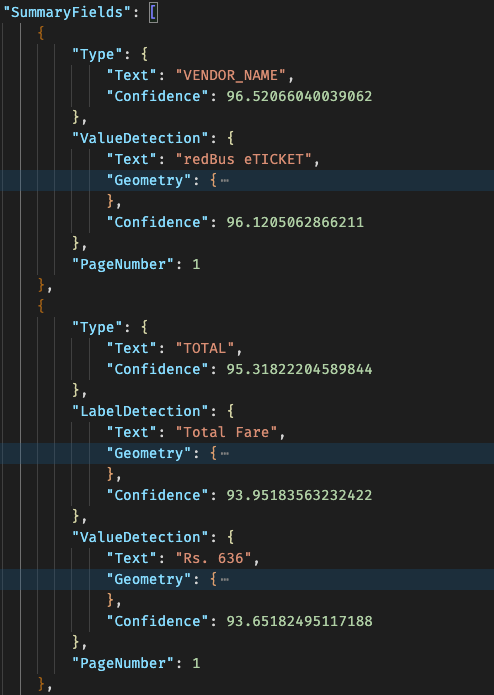
We got some initial results when experimenting, but the results were not up to the mark! The idea was to develop smart layers on top of Textract to get the most accurate data. Once we get the data, we rely on an internally developed intelligent layer to achieve maximum accuracy without increasing the error rate.
This is all good, show me the NUMBERS!

What is the accuracy now?
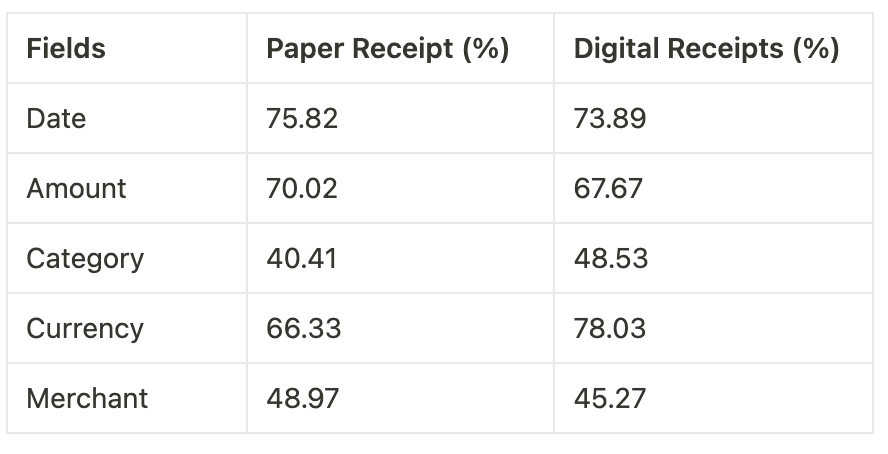
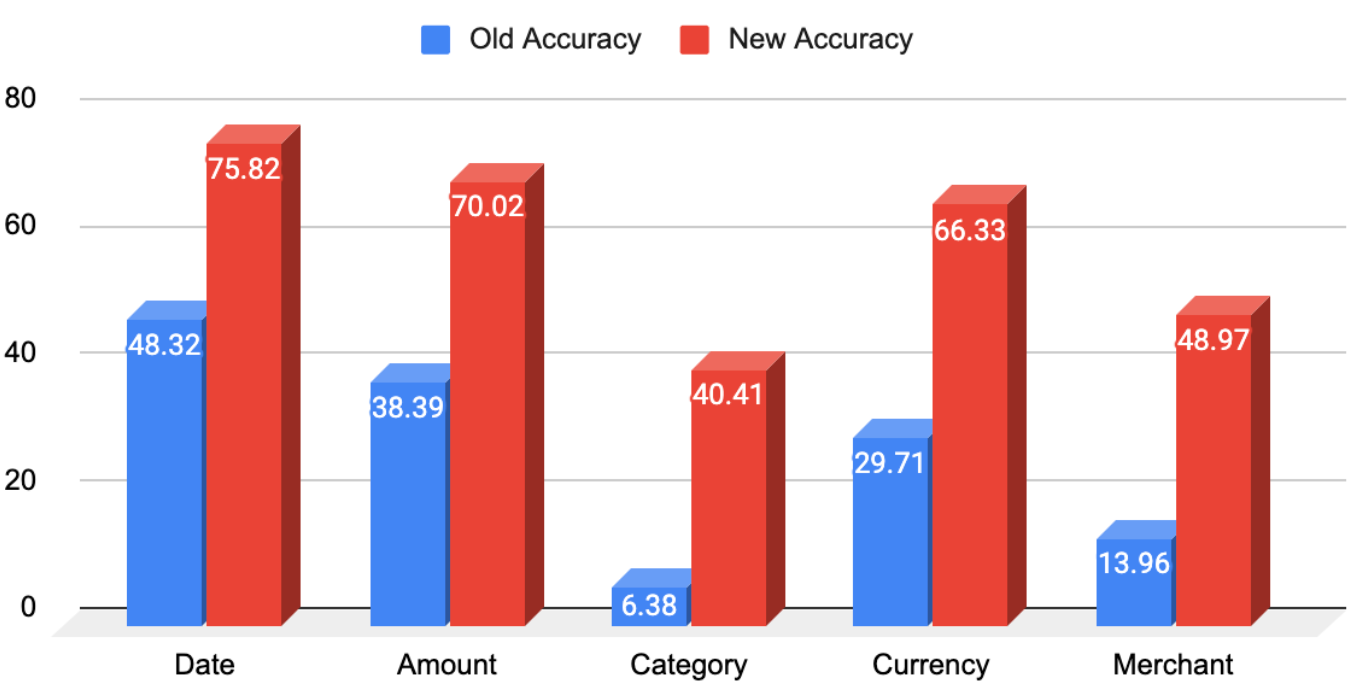
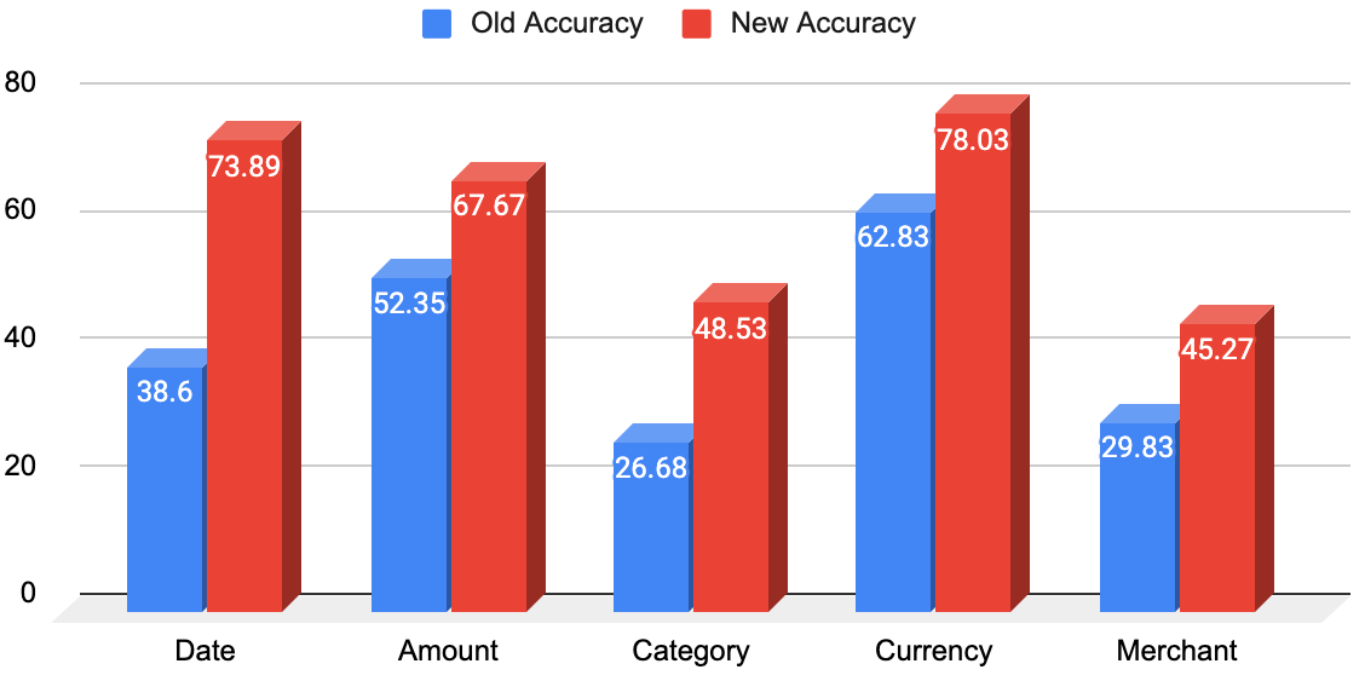
The Results
The accuracy of the date field for receipts was insane, it went up from 43.46%(paper + digital receipts) to 74.85%, a whopping 72.22% increase.
Amount fields` accuracy increase was a solid 51.53% (from 45.37% to 68.84%)
The category of the receipt is the most diverse area of extraction, to classify the receipt into categories, a lot of parameters needs to be considered, we had an increase of ~169% (in all honesty the old accuracy was low, from 16.53% to 44.47%)
My Learnings
Textract, a new toy got added to my list of experiments, I will be adding some Sci-Fi features on top of this 🤞
I got a chance to build a new micro-service from scratch in Python
I joined the DE team a year ago as a noob and today I run the show. The things that I take care of now include maintaining the service, building the test infrastructure, analyzing all old services + old test infra deeply and merging all 5+ years of work to a single new service in just a month’s time, sounds awesome right? Of course, it is AWESOME!

One Last Thing
The reason I could build the entire infrastructure in a month is because of our test infrastructure, here is how it looks when run

Our test infrastructure helped us get the clean and slick stats presented before, having the infra helped us push things confidently to production at insane speeds.
The module is strongly backed by our testing infra, from a pocket-size change to a full-fledged feature, everything has to pass through its strict assessment. If it finds anything odd, bang! the scripts will pinpoint the failing test cases and notify the changes are not yet production-ready. All of this is automated, sounds fascinating right? Yes, it actually is! (An article about that is coming soon)