
Policy Migration: The Final Boss Fight
And That's How We Migrated Policies

Introduction
Hi there! I’m Devadathan—though most folks simply call me Dev. I’m currently working as an MTS in the Platform Engineering Team at Fyle. I joined as an engineering intern in May 2024, and soon after, in August, I took on my first major initiative.
This post is about that initiative—Migrating the Final Piece of Policies—which taught me valuable lessons and exposed me to real-world engineering challenges. Who knows? Maybe future me will stumble across this post and feel a spark of nostalgia—or even find some inspiration!
What Are Policies, Anyway?
Before diving into the technical details of this initiative, let’s start with a quick understanding of what policies are. Policies are a major part of our product and one of the most widely used features across organizations. They play a critical role in ensuring compliance and smooth expense management.

I like to think of policies as a combination of rules and actions designed to ensure expense compliance. The rules define when a policy should be triggered, and the actions specify what happens once it’s triggered.
Here’s a simple example to explain. Imagine I run a company, and Bob, one of my employees, wants to file an expense. He creates an expense of $10. No big deal—Charlie, our only accounting person, approves it without much scrutiny. After all, Charlie’s busy and doesn’t have time to review each expense in detail.
Now here’s the problem: Bob could technically file any expense—including personal ones—and it might slip through this loophole. (Don’t worry, Bob’s a good guy—we’re just imagining worst-case scenarios here for the sake of example.)
Here's where policies come in. I can set up a policy to block, flag, or assign expenses to me for approval if they exceed $10 and aren’t categorized under “Office Supplies.” I can also make receipts mandatory for all expenses, preventing any false claims.
So, in essence, a policy is a set of rules paired with specific actions:
Rule: If the expense amount is > $10 and the category is not “Office Supplies”
Action 1: Flag the expense
Action 2: Assign it to me for approval
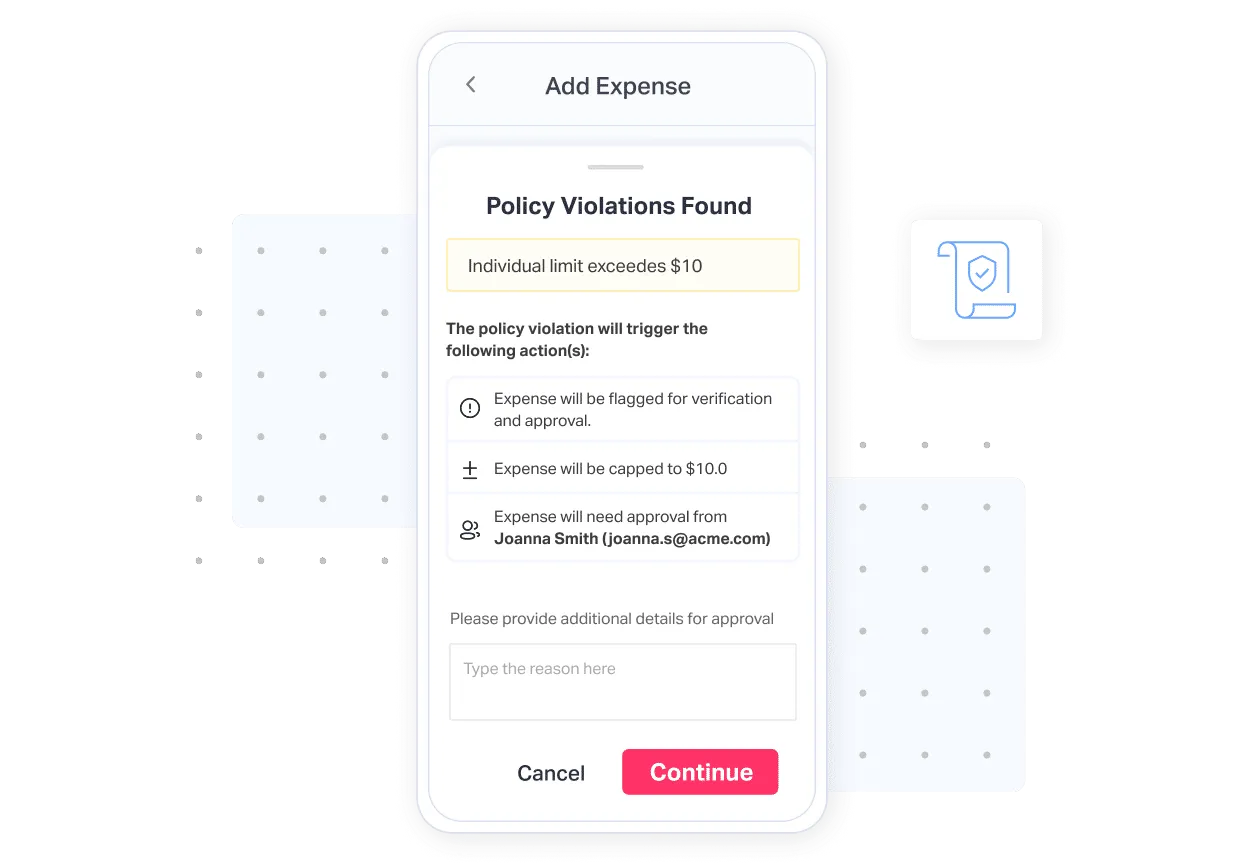
This is just a basic example of what policies can do. In reality, policies are one of the most complex areas of our product—both from a product and engineering perspective.
PS: Want to dive deeper into policies at Fyle? Check out this fantastic blog by Rahul Radhakrishnan: Expense Policy in Fyle.
The Initiative
What Was It About?
Now, let's get to the heart of the matter. What was the initiative all about?
At Fyle, we have two infrastructures—let's call them (because why not throw in a little flair):
The Matrix (our older codebase and infrastructure), and
The Nexus (our newer, more performant infrastructure).
The goal is to migrate as much as possible from the legacy codebase and infrastructure (yes, The Matrix) to the newer one (yes, The Nexus). This is an ongoing process, and most of the work for policies was already done—except for one final, tricky piece: let's call it the policy result application.
My task? To migrate this final, and yet still complicated, part of policies to the new Nexus infrastructure.
Breaking It Down
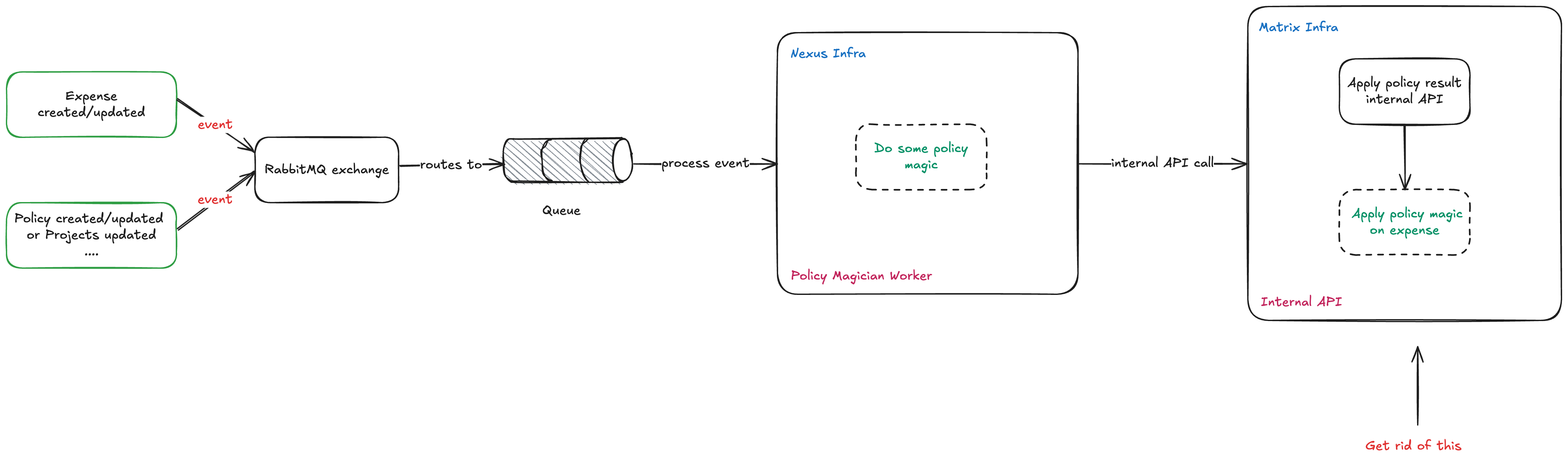
Here's a very high-level (don't take it for granted) overview of how things worked:
When something happens with an expense or policy (like creating or updating them)—our system springs into action and processes it asynchronously.
Then the policy magician does its magic behind the scenes 🪄
Finally, the expense gets updated based on what the policy magician decided.
Once the result is calculated, it is applied to the relevant expenses.
Previously, this result application step relied on an internal HTTP API call to the Matrix infrastructure (the old one). My task was to migrate this process to the Nexus infrastructure (the latest and greatest one), eliminating the need for an API call and ensuring the application happens directly within the worker.
Why was this change needed? Several reasons:
The internal API calls introduced networking overhead, slowing down the process.
It caused frequent deadlock errors and timeouts due to differences in how things worked across infrastructures.
Migrating this step was essential for future scalability and improving overall performance.
There were several bugs in this area, especially related to the approval workflow, which we had to address now.
This shift was key to making the process faster, more reliable, and better aligned with the new infrastructure.
The Starting Days

As I mentioned earlier, this was my first major initiative as an intern. While I had worked on smaller tasks before, this one felt intimidating from the start.
Even before I began, my manager, Kartikey Rajvaidya, and my mentor, Kirti Gautam, mentioned that a few others had attempted this initiative before but had to deprioritize it for various reasons. I still remember Kirti saying in our first call that this was like performing a heart transplant—no big deal, just critical to the system!
My first step was to thoroughly understand the policy flow. I spent about a week digging into how policies work—covering policy computation, result application, and every piece in between. Since the internal API was written in Java, I often found myself toggling back to IntelliJ for clarity whenever I hit a roadblock.
It felt like tackling a LeetCode hard problem (no exaggeration). The sheer amount of application logic present was insane, with all kinds of data structures—sets, hashmaps, lists—you name it, it was all there. The complexity was compounded by rules like, if this happens, then that, but if both happen, then do this instead. Thankfully, I had some resources to guide me, including a previous PR that shed light on parts of the flow. Still, there was plenty I had to figure out myself.
To make it manageable, I broke the migration into smaller tasks based on the flow in the existing codebase. I started tackling them one by one. For someone new to the product, it was tough. I had to double-check everything to ensure I didn’t miss anything.
Each task followed the cycle of:
Local testing to verify the changes.
Staging testing to ensure the updates worked in a near-production environment.
Creating the PR for the task.
Reviewing the PR, incorporating feedback, and iterating on the changes as needed.
Slowly but steadily, I closed tasks one step at a time.
Testing
Given the significance of this change, we couldn't afford mistakes—it had to be thoroughly tested before going live. During my initial testing, I identified a few flaws and fixed them quickly. Since this change touched multiple areas of the product, I knew it was crucial to get more eyes on it.
To ensure comprehensive testing, I created a detailed testing document covering all the scenarios I could think of and shared it with my teammates. They tested it rigorously and pointed out some minor issues, which I addressed right away.
A big shoutout to Kirti, Yash, Prabhakar, and Prakash for their extensive testing efforts and for helping ensure nothing critical slipped through.
Production Release and the P0 Surprise
When it was time to make this live, I was both excited and nervous. The extensive testing and positive feedback gave me confidence, but there was always that lingering worry about some rare corner case I might have missed. Still, I trusted the process and moved forward.

We deployed—and, as shown in the image, we could hardly believe it finally happened! Everything went smoothly—no issues yet, and everything was working as expected. We carefully monitored Grafana dashboards throughout the day after the release to ensure nothing unexpected occurred.
Well, like the old saying goes, "Anything that can go wrong will go wrong"—and sure enough, something did. To my luck (or lack of it), it came as a P0 issue.
I had missed a condition where it shouldn’t have been—a simple one-liner change, but just like a missing semicolon, it had the potential to cause a big issue. The problem surfaced around 8 PM IST, just as I had stepped out. When I saw the Slack notification and realized it was a P0, I didn’t immediately connect it to the policies, but deep down, I had a hunch it might be.
Huge thanks to Kirti and the team for stepping in and fixing it quickly despite my absence. Their support ensured the situation was resolved without escalating further.
After the deployment, we discovered a few additional, non-critical issues that still needed attention. I spent the following weeks fixing them to make sure everything was stable and in place.
Key Takeaways
After monitoring the final fix for a week with no issues, we knew it was a success and it was time to wrap up this saga. Here's a snapshot of the metrics we observed:

To be honest, it wasn’t easy, especially in the early days. For someone new like me, the complexity of the logic and the interconnectedness of various product areas felt overwhelming. There were times I questioned if I could pull it off, but with time and support, I gradually began to navigate through it.
Looking back, I’m glad I took on such a complex challenge early in my journey. It gave me a deeper understanding of the product, the codebase, and the various components at play. Along the way, I learned valuable lessons—from testing and debugging to understanding the infrastructure better and, yes, encountering some data structures cleverly embedded in the application code.
From that point on, whenever an issue or query came up in policies, I knew exactly what needed to be done.
I truly can’t thank my amazing team enough: Kartikey, Kirti, Prabhakar, Prakash, Yash, Shreyansh and everyone else. Their support made all the difference in making this possible.
Thanks for reading! Have a great time until the next one with more code, more stories, and more blogs!
Intresting article Dev.