
My server killed my client

Recently, we experienced a drastic lag in one of our services, due to which some of our asynchronous data export jobs slowed down. Some calls that we expect to finish in 100ms were taking 10+ seconds. Interestingly enough, it turned out to be a case where our server was killing our client (of course, in context of http requests).
This blog post follows our debugging adventure and findings from this incident. Read on if you don't wish to waste hours debugging for anomalies in your http requests.

Our setup and the debugging
The change which caused the latency involved adding a new java web service - lets call it moriarty - and calling it from one of our other python web services, say sherlock.

We expect call_moriarty() to take less than 100 ms, but debugging showed it was randomly taking 7+ seconds in some cases. This latency was getting magnified to minutes due to multiple such requests being made in a serial manner.
To debug further, we added timing logs in moriarty - at all steps of the api call. Here, to our surprise, we found that everything was under milliseconds!
With a heavy heart, we ditched the moriarty's low performance hypothesis and decided to log timings in a more fine-grained step-by-step way on the client service (sherlock) code.
In sherlock, the http utility function which calls moriarty, did 2 things evidently:
1) making the api call
2) loading result into a dictionary and returning it
Ditching the pythonicity, we split the code into multiple lines and timed each step to see which one was causing the latency

To our surprise, step-2 was the cause of the delay that we were seeing. It is always the ones you least expect!
After this mildly surprising revelation, we started doubting whether this could be some performance kink of the builtin libs like json or other de-facto standard libs like requests - that we have been trusting blindly so far.
We began with json first. Googled around, and found some evidence similar to our case where json.loads() was taking un-expectedly high time for long strings. On trying other json libs like simplejson, yljl - we did not see any improvement in our case. All libs gave similar timings for json deserialization.
Our next suspect was str() which anyways, was only present for some extra type safety. For testing this, we stored str(response.text) to a separate variable and measured timing of this step to find - that this simple assignment, was actually taking all the time. Rest all steps were under 1 ms. Although, on removing str() also we got same timings.
This meant that the http call (and hence moriarty) was not the cause of latency. Instead, reading the response content and storing it in a variable was, strangely, taking all the time - 10 seconds in some cases.
The issue
Eager to end this rather long chain of debugging surprises, we googled around this behavior of python requests lib and stumbled upon the exact issue affecting us : https://github.com/psf/requests/issues/2359. Gist of the issue is as follows.
Python requests library can take an awful lot of time to detect content encoding when the response size is big and encoding is not specified in the response headers. This is, in turn, due to an issue in another library - chardet - which requests depends upon, to detect response encoding.
We just had to enable debug logs to see this chardet regression in action, in our case.
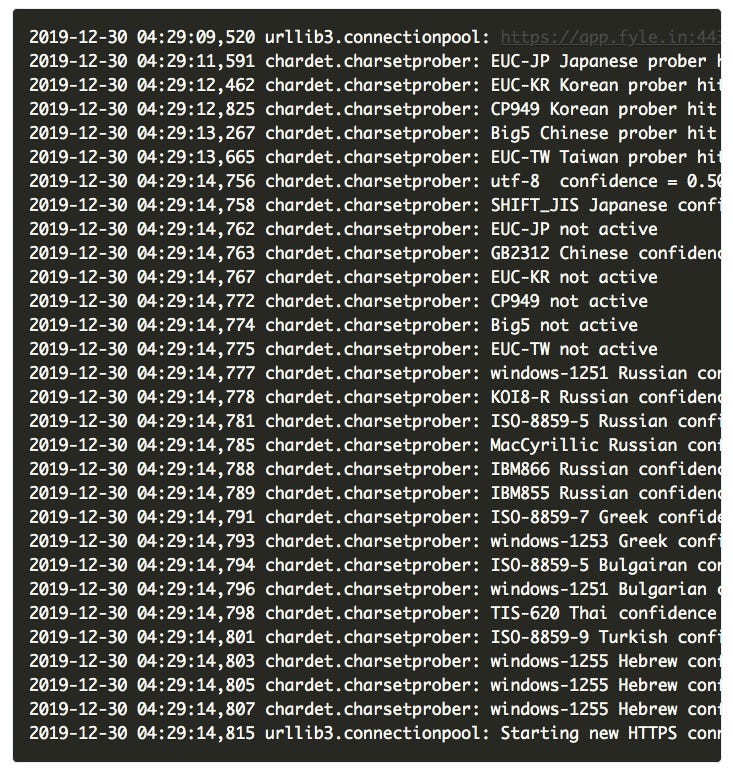
Just to be super-sure that this issue was the cause of latency, we patched it on client side by manually assigning encoding to response before calling response.text and ran our timing tests again.

And as expected (or just prayed for, at this time), everything was blazing fast again. That assignment step took less than 10 ms now.
The fix
So, we were finally successful in isolating the issue, but assigning the content encoding on client would not be the right way to fix it. The server/service should take care of including content encoding with response headers.
We fixed moriarty APIs by replacing the first header above, with the second one in response headers and python requests was happy again - latency was gone !
Now that we were wiser, we made sure our other services also followed suit. We decided to audit the code of all our services looking for similar latencies and ended up finding cases where this bug was causing latencies of upto 15 seconds on production.
Some reasons as to why this issue - which was the reason for significant performance regression - surfaced so late in our case :
dependence on response size.
In APIs where response size is not huge, the latency caused is not substantial, hence goes un-noticed.arbitrary nature / dependence on response content
Even in cases of bigger response size, in-fact for most of such cases, we did not see latency consistently. Only 1 of every 4 responses took time to deserialise. This apparently had more to do with response content (special characters, un-conventional encodings etc.) than size - just that bigger response size aggravates this issue.frequency and timing of calls
This issue would not have been so prominent had the latency not been magnified due to multiple consecutive api calls.
Repeating for emphasis here. This hideous issue, present in one of the most used python libs out there, had slowed down our workloads by a factor of ~x1000 !!
Nevertheless, it was one nice debugging adventure resulting in findings which will save us an awful lot of head-scratches in future.
If you enjoy taking up such thrilling bug chases, we might have a job for you. Drop us a mail at careers@fyle.in ! :)